
 400-626-7377
400-626-7377
python如何實現日常工作自動化?
大多數作業具有可以自動執行的重復性任務,從而節省了一些寶貴的時間。這使自動化成為一項關鍵技能。一小撮熟練的自動化工程師和領域專家也許可以自動化整個團隊中許多最繁瑣的任務。那么python如何實現日常工作自動化?在本文中,我們將探討使用Python(一種功能強大且易于學習的編程語言)的工作流自動化的基礎。我們將使用Python編寫一個簡單而有用的自動化小腳本,該腳本將清理給定的文件夾并將每個文件放入相應的文件夾中。

我們的目標不是在一開始就編寫完美的代碼或創建理想的體系結構。我們也不會建立任何“非法”的東西。相反,我們將研究如何創建一個腳本,該腳本會自動清理給定的文件夾及其所有文件。
一、自動化領域和起點
自動化技術適用于大多數領域。對于初學者來說,它有助于完成諸如從一堆文檔中提取電子郵件地址之類的任務,以便您可以進行電子郵件爆炸。或更復雜的方法,例如優化大型公司內部的工作流程和流程。
當然,從小型的個人腳本到替代實際人員的大型自動化基礎架構涉及學習和改進的過程。因此,讓我們看看您可以從何處開始旅程。
簡單自動化
簡單的自動化實現了快速直接的切入點。這可以涵蓋小的獨立過程,例如項目清理和目錄內文件的重組,也可以包括工作流的某些部分,例如自動調整已保存文件的大小。
公共API自動化
公共API自動化是最常見的自動化形式,因為如今我們可以使用對API的HTTP請求來訪問大多數功能。例如,如果您想在家中自動為自制的智能花園澆水。
為此,您想檢查當天的天氣,看看是否需要澆水或是否有雨來。
API逆向工程
在實際的漫游器中,基于API逆向工程的自動化更為常見,在下面的“道德注意事項”部分中,該圖表的“ Bot Imposter”部分中也是如此。
通過對API進行反向工程,我們可以了解應用程序的用戶流程。一個例子是登錄在線瀏覽器游戲。
通過了解登錄和身份驗證過程,我們可以使用自己的腳本來復制該行為。然后,即使他們自己不提供應用程序,我們也可以創建自己的接口來使用該應用程序。
無論您要采用哪種方法,請始終考慮它是否合法。
您不想惹麻煩,對嗎?
二、道德考量
GitHub上的某個人曾經與我聯系并告訴我:
“喜歡和參與是數字貨幣,您正在貶值它們。”
這讓我感到困惑,并讓我質疑我為此目的而構建的工具。
這些互動和參與可以自動化并“偽造”的事實越來越多,這導致了社交媒體系統的扭曲和破壞。
如果人們不使用漫游器和其他互動系統,那么產生有價值和優質內容的人將對其他用戶和廣告公司不可見。
我的一個朋友想出了以下但丁與但丁的“地獄九圈”的聯系,在每一步中,隨著成為社會影響者的步伐越來越近,您將越來越不了解整個系統的實際破壞力。
我想在這里與您分享這件事,因為我認為這是我與InstaPy積極與網紅合作時親眼所見的非常準確的代表。
等級1:凌波-如果您;
等級2:調情 -當您手動喜歡并關注盡可能多的人時,請他們跟著您回去/喜歡您的帖子;
等級3:陰謀 -當您加入電報組喜歡和評論10張照片,因此接下來的10個人將喜歡和評論您的照片;
等級4:不忠 -當您使用低成本的虛擬助手代表您喜歡和關注時;
等級5:欲望-當您使用機器人給予喜歡,但沒有得到任何回報(但您不為此付費(例如,Chrome擴展程序));
級別6:濫交-當您使用機器人給予50多個喜歡得到50多個喜歡的人,但您無需為此付費-例如,Chrome擴展程序;
等級7:貪婪或極端貪婪 -當您使用漫游器在200-700張照片之間點贊/關注/評論時,忽略了被禁止的機會;
等級8:賣淫 -當您支付未知的第三者服務進行自動對等時喜歡/關注您,但他們使用您的帳戶喜歡/關注;
第9級:欺詐/異端 -當您購買關注者和喜歡并嘗試將自己賣給有影響力的品牌時。
社交媒體上的惡意攻擊程度如此之高,以至于如果您不進行機器人操作,那么您將被困在Limbo 1級,相對于同齡人而言,追隨者的成長率和參與度都不高。
在經濟學理論上,這被稱為囚徒困境和零和博弈。如果我不機器人,而你又機器人,你贏了。如果您不是機器人,而我是機器人,我會贏。如果沒有機器人,那么所有人都會贏。但是,由于沒有人人都不要機器人,所以沒有人能贏。
注:永遠不要忘記整個工具對社交媒體的影響。
我們希望避免處理道德問題,而仍在此處從事自動化項目。這就是為什么我們將創建一個簡單的目錄清理腳本來幫助您整理凌亂文件夾的原因。
三、創建目錄清理腳本
現在,我們要看一個非常簡單的腳本。通過基于文件擴展名將這些文件移動到相應的文件夾中,它會自動清理給定目錄。
因此,我們要做的就是:
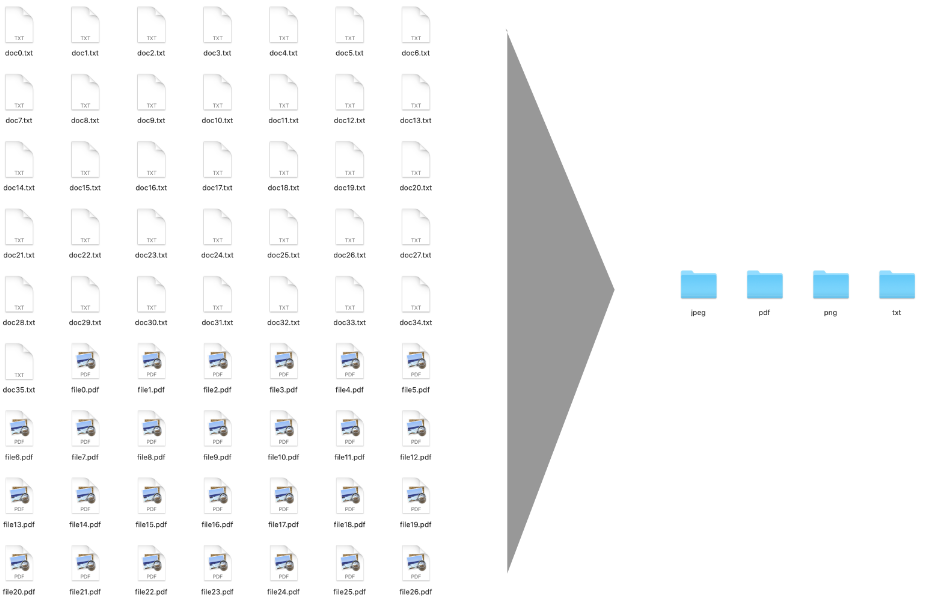
1.設置參數解析器
由于我們正在使用操作系統功能(如移動文件),因此需要導入os庫。除此之外,我們還希望使用戶可以控制要清理的文件夾。我們將argparse為此使用庫。
import os
import argparse
導入兩個庫之后,我們首先設置參數解析器。確保為每個添加的參數提供描述和幫助文本,以在用戶鍵入內容時為用戶提供有價值的幫助--help。
我們的論點將命名為--path。名稱前面的雙破折號告訴庫這是一個可選參數。默認情況下,我們要使用當前目錄,因此將默認值設置為"."。
parser = argparse.ArgumentParser(
description="Clean up directory and put files into according folders."
)
parser.add_argument(
"--path",
type=str,
default=".",
help="Directory path of the to be cleaned directory",
)
# parse the arguments given by the user and extract the path
args = parser.parse_args()
path = args.path
print(f"Cleaning up directory {path}")
這樣就完成了參數解析部分–它非常簡單易讀,對吧?
讓我們執行腳本并檢查錯誤。
python directory_clean.py --path ./test
=> Cleaning up directory ./test
執行后,我們可以看到目錄名稱已完美打印到控制臺。
現在讓我們使用該os庫來獲取給定路徑的文件。
2. 從文件夾中獲取文件列表
通過使用該os.listdir(path)方法并為其提供有效路徑,我們獲得了該目錄內所有文件和文件夾的列表。
在列出文件夾中的所有元素之后,我們不想在文件夾和文件夾之間進行區分,因為我們不想清理文件夾,而只清理文件。
在這種情況下,我們使用Python列表推導來遍歷所有元素,如果它們滿足作為文件或文件夾的給定要求,則將它們放到新列表中。
# get all files from given directory
dir_content = os.listdir(path)
# create a relative path from the path to the file and the document name
path_dir_content = [os.path.join(path, doc) for doc in dir_content]
# filter our directory content into a documents and folders list
docs = [doc for doc in path_dir_content if os.path.isfile(doc)]
folders = [folder for folder in path_dir_content if os.path.isdir(folder)]
# counter to keep track of amount of moved files
# and list of already created folders to avoid multiple creations
moved = 0
created_folders = []
print(f"Cleaning up {len(docs)} of {len(dir_content)} elements.")
與往常一樣,讓我們確保我們的用戶得到反饋。因此,添加一條打印語句,以向用戶指示要移動多少文件。
python directory_clean.py --path ./test
=> Cleaning up directory ./test
=> Cleaning up 60 of 60 elements.
重新執行python腳本后,我們現在可以看到/test我創建的文件夾包含60個將被移動的文件。
3.為每個文件擴展名創建一個文件夾
現在,下一步也是更重要的一步是為每個文件擴展名創建文件夾。為此,我們要瀏覽所有過濾的文件,如果它們的擴展名沒有文件夾,請創建一個。
該os庫可為我們提供更好的功能,例如拆分給定文檔的文件類型和路徑,提取路徑本身和文檔名稱。
# go through all files and move them into according folders
for doc in docs:
# separte name from file extension
full_doc_path, filetype = os.path.splitext(doc)
doc_path = os.path.dirname(full_doc_path)
doc_name = os.path.basename(full_doc_path)
print(filetype)
print(full_doc_path)
print(doc_path)
print(doc_name)
break
上面代碼末尾的break語句可確保如果目錄中包含數十個文件,我們的終端也不會被發送垃圾郵件。
設置好之后,讓我們執行腳本以查看類似于以下內容的輸出:
python directory_clean.py --path ./test
=> ...
=> ./test/test17
=> ./test
=> test17
現在我們可以看到上面的實現分離了文件類型,然后從完整路徑中提取了部分。
由于我們現在具有文件類型,因此我們可以檢查是否存在具有該類型名稱的文件夾。
在此之前,我們要確保跳過一些文件。如果我們使用當前目錄"."作為路徑,則需要避免移動python腳本本身。一個簡單的if條件可以解決這個問題。
除此之外,我們不想移動“ 隱藏文件”,因此我們也包括所有以點開頭的文件。.DS_StoremacOS上的文件是隱藏文件的示例。
# skip this file when it is in the directory
if doc_name == "directory_clean" or doc_name.startswith('.'):
continue
# get the subfolder name and create folder if not exist
subfolder_path = os.path.join(path, filetype[1:].lower())
if subfolder_path not in folders:
# create the folder
處理完python腳本和隱藏文件后,我們現在可以繼續在系統上創建文件夾。
除了檢查之外,如果在讀取目錄內容時文件夾已經存在,那么一開始,我們需要一種跟蹤已創建文件夾的方法。這就是我們宣布該created_folders = []名單的原因。它將用作跟蹤文件夾名稱的存儲器。
要創建一個新文件夾,該os庫提供了一個名為的方法,該方法os.mkdir(folder_path)采用一個路徑并在那里創建一個具有給定名稱的文件夾。
此方法可能會引發異常,告訴我們該文件夾已存在。因此,我們還要確保捕獲該錯誤。
if subfolder_path not in folders and subfolder_path not in created_folders:
try:
os.mkdir(subfolder_path)
created_folders.append(subfolder_path)
print(f"Folder {subfolder_path} created.")
except FileExistsError as err:
print(f"Folder already exists at {subfolder_path}... {err}")
設置文件夾創建后,讓我們重新執行腳本。
python directory_clean.py --path ./test
=> ...
=> Folder ./test/pdf created.
在第一次執行時,我們可以看到一個日志列表,告訴我們已經創建了具有給定類型的文件擴展名的文件夾。
4.將每個文件移到右子文件夾中
現在的最后一步是將文件實際移到其新的父文件夾中。
使用os操作時要了解的重要一點是,有時無法撤消操作。例如,這就是刪除的情況。因此,首先僅注銷執行腳本將實現的行為是有意義的。
這就是為什么該os.rename(...)方法在這里被評論的原因。
# get the new folder path and move the file
new_doc_path = os.path.join(subfolder_path, doc_name) + filetype
# os.rename(doc, new_doc_path)
moved += 1
print(f"Moved file {doc} to {new_doc_path}")
執行完腳本并查看正確的日志記錄之后,我們現在可以在os.rename()方法前刪除注釋哈希,并最終進行注釋。
# get the new folder path and move the file
new_doc_path = os.path.join(subfolder_path, doc_name) + filetype
os.rename(doc, new_doc_path)
moved += 1
print(f"Moved file {doc} to {new_doc_path}")
print(f"Renamed {moved} of {len(docs)} files.")
python directory_clean.py --path ./test
=> ...
=> Moved file ./test/test17.pdf to ./test/pdf/test17.pdf
=> ...
=> Renamed 60 of 60 files.
現在,此最終執行會將所有文件移動到它們相應的文件夾中,并且無需手動操作即可很好地清理我們的目錄。
在下一步中,我們現在可以使用上面創建的腳本,例如,安排它在每個星期一執行,以清理我們的Downloads文件夾以獲得更多結構。
以上即是關于python如何實現日常工作自動化的全部內容,想了解更多關于python的信息,請繼續關注中培偉業吧。
相關閱讀
- 怎樣提高自己的Python編程能力?08-21
- Python數據分析與數據挖掘適合哪些人?07-12
- 學python可以做什么,有什么用?07-12
- 想入大廠,學Python核心編程05-13
- Python和Java哪個更值得學?03-27





-
全國報名服務熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377
京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377