
 400-626-7377
400-626-7377
容器云平臺OpenShift3.11集群部署歷險記(下)
讓我們向天坑發起沖刺吧!
當你在為前面幾步0個failed沾沾自喜的時候,天坑降臨了,在執行/openshift-ansible-release-3.11/playbooks/openshift-master/config.yml腳本時,一直會卡在這步:
Wait for all control plane pods to come up and become ready,腳本不斷的在等待openshift的pod容器的相應,經過漫長的等待,終于跳出了天坑的錯誤提示信息:
failed: [master01.okd.com] (item=etcd) => {"ansible_loop_var": "item", "attempts": 72, "changed": false, "item": "etcd", "msg": {"cmd": "/sr/bin/oc get pod master-etcd-master01.okd.com -o json -n kube-system", "results": [{}], "returncode": 1, "stderr": "The connection to the server master01.okd.com:8443 was refused - did you specify the right host or port? ", "stdout": ""}}
當然腳本還會繼續嘗試等待響應,3次失敗后,宣告部署失敗,明晃晃的一個failed出現在master01.okd.com主機上,但不可思議的是報錯信息是8443端口拒絕,我們明明在之前已經開放了8443端口呀,怎么會8443端口拒絕響應呢?我頓時傻眼了,為了驗證,我用curl master01.okd.com:8443請求,結果就是8443 refused,我用同樣的方法測試curl master01.okd.com:22請求,很快主機上的ssh就回復了。
很多小伙伴到這里不堪忍受就放棄了,而上面這個錯誤我在國內和國外的貼吧里找了一遍也沒有正確的解決方法。經過2天的思考,忽然我靈光乍現,一個念頭出現了:是不是因為8443端口上根本就沒有程序在執行,而不是端口沒有開放而造成的refused呢?
我用命令cat /etc/sysconfig/iptables看了一下,發現openshfit安裝到目前的地步,只占用了8444端口,而8443端口處于待命閑置狀態。那是不是我的docker準備安裝的鏡像缺失造成playbook沒有運行這個缺失的鏡像在8443端口上待命呢?
想到這里,我不斷的在網上驗證我的想法,終于在國外一個不起眼的貼吧里找到了openshift3.11集群部署需要的docker鏡像清單,我比對了一下,發現缺失了如下這些鏡像:
docker pull docker.io/cockpit/kubernetes:latest
docker pull docker.io/openshift/prometheus-node-exporter:v0.16.0
docker pull quay.io/coreos/kube-rbac-proxy:v0.3.1
docker pull quay.io/openshift/origin-
cluster-monitoring-operator:v3.11
docker pull docker.io/ansibleplaybookbundle/
origin-ansible-service-broker:v3.11
docker pull quay.io/coreos/prometheus-
config-reloader:v0.23.2
docker pull docker.io/openshift/prometheus-
alertmanager:v0.15.2
docker pull docker.io/openshift/prometheus:v2.3.2
docker pull quay.io/coreos/kube-state-
metrics:v1.3.1
docker pull docker.io/openshift/origin-
docker-builder:v3.11
是不是這其中的某個鏡像沒有而造成8443 refused的問題呢?死馬當活馬醫,我抱著試試看的心理,再次在三個鏡像中安裝了上面這些被我遺漏的鏡像,之后再次來到第十二步集群安裝,來到/openshift-ansible-release-3.11/playbooks/openshift-master/config.yml鬼門關時,一顆心都是懸著的,過了72次的retries,一個打臉的報錯又出現了:
failed: [master01.okd.com] (item=etcd) => {"ansible_loop_var": "item", "attempts": 72, "changed": false, "item": "etcd", "msg": {"cmd": "/usr/bin/oc get pod master-etcd-master01.okd.com -o json -n kube-system", "results": [{}], "returncode": 1, "stderr": "The connection to the server master01.okd.com:8443 was refused - did you specify the right host or port? ", "stdout": ""}}
難道還是不對嗎?一個master01.okd.com的failed砸了過來,我基本已經崩潰了,在心灰意冷的情況下,我想再試2次,不行我就放棄吧!
第二次一樣failed,心情再次跌落到深淵,為了安慰自己便再試最后一次,在第三次執行/openshift-ansible-release-3.11/playbooks/openshift-master/config.yml腳本時我已經麻木了……
俗話說得好,“山重水復疑無路,柳暗花明又一村”。正當我面對天坑打道回府之際,奇跡出現了,我截屏了這一瞬間的時刻,大家看下圖:
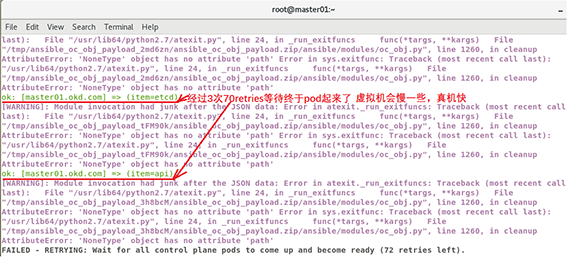
在master01.okd.com上終于部署成功了,我經歷了3個70多次的retries后終于看到了勝利的曙光:

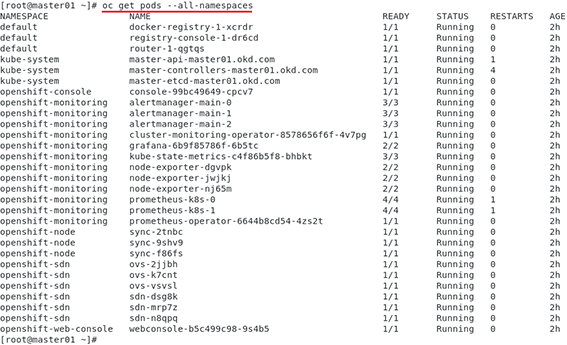
后面就一帆風順了,全部腳本執行完成后我執行oc get nodes查看集群node運行情況:

并執行oc get pods --all-namespaces查看pod的running狀態:
在node01.okd.com和node02.okd.com上執行docker ps查看集群運行的情況:
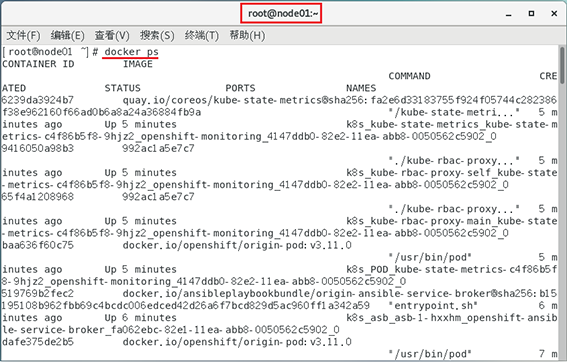
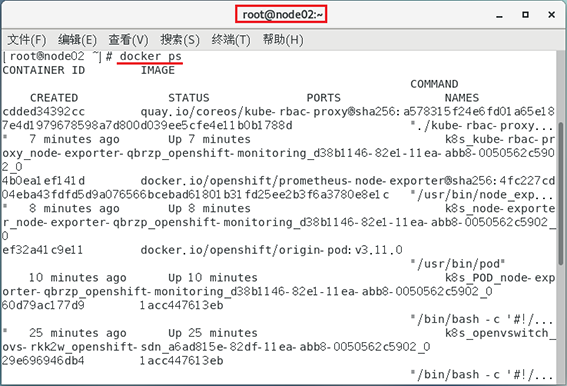
三臺機器已經協同運行了!
我在master01.okd.com主機上創建了登錄賬戶:
htpasswd -b /etc/origin/master/htpasswd admin admin
oc login -u system:admin
oc adm policy add-cluster-role-to-user cluster-admin admin
最后在windows系統的客戶端的hosts文件設置了openshift地址并訪問:
C:WindowsSystem32driversetchosts
192.168.122.159 master01.okd.com
192.168.122.158 node01.okd.com
192.168.122.160 node02.okd.com
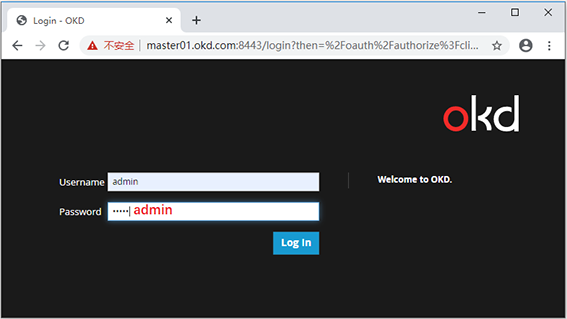
久違的畫面出現了,至此我們終于成功了!
再回過頭來想想,剛才的天坑是怎么造成的,主要有如下幾點:
1.openshift3.11需要的鏡像準備不全。
2.在虛擬機環境下由于資源有限,從而造成一直等到pod響應,因為容器啟動是要時間的,因此第一次失敗很正常,如果您在真機上運行說不定一次就能通過。但不要緊,后臺的pod正在啟動中,只要playbook檢測到了就會通過,在我經過3次嘗試后,后臺的pod終于啟動成功了,很多小伙伴就是由于耐不住寂寞,而放棄了,當然如果您的鏡像準備不全的話,嘗試10000次也是天坑的報錯打臉。
至此,我的容器云openshift3.11集群部署歷險記就寫到這里,希望要安裝容器云的小伙伴可以踩著我的尸體順利完成!
- 上一篇:專家視角:網絡安全基本原理淺析
- 下一篇:遠程服務暫時性錯誤:采用重試是否真的有效
相關閱讀





-
全國報名服務熱線
 400-626-7377
400-626-7377
-
熱門課程咨詢
 在線咨詢
在線咨詢
-
微信公眾號
 微信號:zpitedu
微信號:zpitedu
京ICP備13024721號-1
 京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377
京公網安備11010602007294號 增值電信業務經營許可證:京B2-20201348 全國統一報名專線:400-626-7377